
DotLucene搜索引擎之搜索索引Demo
在上篇文章我们说了怎么建立索引,现在说的是怎么搜索这个索引,最主要的我们是要理解startAt的含义,理解了他什么问题都解决了。还有这个例子的分页很经典,我发现google和baidu用
在上篇文章我们说了怎么建立索引,现在说的是怎么搜索这个索引,最主要的我们是要理解startAt的含义,理解了他什么问题都解决了。还有这个例子的分页很经典,我发现google和baidu用的都是这个分页方法。主要就两个方法,一个search()方法,主要是显示当前页的搜索记录
1 protected void search()
protected void search()
2

 {
{
3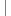 DateTime start = DateTime.Now;//搜索的开始时间
DateTime start = DateTime.Now;//搜索的开始时间
4 //得到索引所在的目录,我们在上个console程序里把索引放到了index目录下
5 string indexDirectory = Server.MapPath("index");
6 //创建个索引搜索器
7 IndexSearcher searcher = new IndexSearcher(indexDirectory);
8 //分词并解析索引的text字段以便搜索
9 Query thisQuery = QueryParser.Parse(this.Query,"text",new StandardAnalyzer());
10 //为要绑定输出到页面的results建立几列
11 this.Results.Columns.Add("path",typeof(string));
12 this.Results.Columns.Add("sample",typeof(string));
13 this.Results.Columns.Add("title",typeof(string));
14 //开始搜索
15 Hits hits = searcher.Search(thisQuery);
16 //得到搜索返回的记录总数
17 this.total = hits.Length();
18 //创建一个高亮
19 QueryHighlightExtractor highlighter = new QueryHighlightExtractor(thisQuery, new StandardAnalyzer(), "<B>", "</B>");
20 //初始化startAt,以便得到要显示的结果集
21 this.startAt = initStartAt();
22 //得到当前页要显示的记录数量,包括以前所有页的记录数,这样把他与this.startAt结合就能够很好的知道当前页要显示的记录数了
23 int resultsCount = smallOf(this.total,this.startAt+this.maxResults);
24 //开始循环得到当前页要显示的记录
25 for (int i = this.startAt; i < resultsCount; i++)
26
 {
{
27 //得到每一行Hits的Document,因为Hits的没一行都是个Document对象
28 Document doc = hits.Doc(i);
29 //得到doc里面的列path的值
30 string path = doc.Get("path");
31 //再得到这个路径在web程序的路径,我们原来把文档放到了web根目录的documents目录下的
32 string location = Server.MapPath(@"documents\"+path);
33 //用StreamReader读取文档,因为我们不能够直接从索引中得到text字段的值,因为我们建立索引的时候没有存储他的
34 string plainText;
35 using (StreamReader sr = new StreamReader(location, System.Text.Encoding.Default))
36 {
37 plainText = ParseHtml(sr.ReadToEnd());
38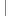 }
}
39 //为结果集DataTable,Results添加个新行
40 DataRow dr = this.Results.NewRow();
41 dr["title"] = doc.Get("title");
42 dr["path"] = @"documents/" + path;
43 dr["sample"] = highlighter.GetBestFragment(plainText,80);
44 //把行添加进DataTable
45 this.Results.Rows.Add(dr);
46 }
47 //循环完毕,关闭搜索
48 searcher.Close();
49 //搜索花费多少时间
50 this.duration = DateTime.Now - start;
51 //给fromItem赋值,他总是startAt+1
52 this.fromItem = this.startAt + 1;
53 //给toItem赋值
54 this.toItem = smallOf(this.total,this.startAt+this.maxResults);
55
56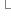 }还有就是一个Paging属性,他的作用就是分页,输出分页的html这个属性很经典
}还有就是一个Paging属性,他的作用就是分页,输出分页的html这个属性很经典
1/**//// <summary>
2 /// 开始分页
3 /// </summary>
4 /// <returns></returns>
5 protected DataTable Paging
6 {
7 get
8 {
9 //知道了startAt,分页也很容易了,现在根据startAt得到当前是第几页,注意,现在这里的页数也是暂时从0开始的
10 int pageNumber = (this.startAt + this.maxResults - 1) / this.maxResults;
11 DataTable dt = new DataTable();
12 dt.Columns.Add("html");
13 DataRow dr = dt.NewRow();
14 //暂时得到当前页的html连接,注意这里当真正显示页数的时候要+1
15 dr["html"] = pagingNumberHtml(startAt,pageNumber+1,false);
16 dt.Rows.Add(dr);
17 //前面显示10页,如果有的话
18 int previousPagesCount = 10;
19 //循环把前面页的html连接插到前面去
20 for (int i = pageNumber - 1; i >= 0 && i >= pageNumber - previousPagesCount; i--)
21 {
22 DataRow r = dt.NewRow();
23 r["html"] = pagingNumberHtml(i*this.maxResults,i+1,true);
24 dt.Rows.InsertAt(r,0);;
25 }
26 //后面也显示10页,如果有的话
27 int nextPagesCount = 10;
28 for (int i = pageNumber + 1; i <= this.pageCount && i <= pageNumber + nextPagesCount; i++)
29 {
30 DataRow r = dt.NewRow();
31 r["html"] = pagingNumberHtml(i*this.maxResults,i+1,true);
32 dt.Rows.Add(r);
33 }
34 //添加下一页的超级连接
35 DataRow lastRow = dt.NewRow();
36 lastRow["html"] = "<a href='Search.aspx?q="+this.Query+"&start="+(pageNumber+1)*this.maxResults+"'>下一页</a>";
37 dt.Rows.Add(lastRow);
38 return dt;
39
40 }
1
protected void search()2
{3
DateTime start = DateTime.Now;//搜索的开始时间4
//得到索引所在的目录,我们在上个console程序里把索引放到了index目录下5
string indexDirectory = Server.MapPath("index");6
//创建个索引搜索器7
IndexSearcher searcher = new IndexSearcher(indexDirectory);8
//分词并解析索引的text字段以便搜索9
Query thisQuery = QueryParser.Parse(this.Query,"text",new StandardAnalyzer());10
//为要绑定输出到页面的results建立几列11
this.Results.Columns.Add("path",typeof(string));12
this.Results.Columns.Add("sample",typeof(string));13
this.Results.Columns.Add("title",typeof(string));14
//开始搜索15
Hits hits = searcher.Search(thisQuery);16
//得到搜索返回的记录总数17
this.total = hits.Length();18
//创建一个高亮19
QueryHighlightExtractor highlighter = new QueryHighlightExtractor(thisQuery, new StandardAnalyzer(), "<B>", "</B>");20
//初始化startAt,以便得到要显示的结果集21
this.startAt = initStartAt();22
//得到当前页要显示的记录数量,包括以前所有页的记录数,这样把他与this.startAt结合就能够很好的知道当前页要显示的记录数了23
int resultsCount = smallOf(this.total,this.startAt+this.maxResults);24
//开始循环得到当前页要显示的记录25
for (int i = this.startAt; i < resultsCount; i++)26
{ 27
//得到每一行Hits的Document,因为Hits的没一行都是个Document对象28
Document doc = hits.Doc(i);29
//得到doc里面的列path的值30
string path = doc.Get("path");31
//再得到这个路径在web程序的路径,我们原来把文档放到了web根目录的documents目录下的32
string location = Server.MapPath(@"documents\"+path);33
//用StreamReader读取文档,因为我们不能够直接从索引中得到text字段的值,因为我们建立索引的时候没有存储他的34
string plainText;35
using (StreamReader sr = new StreamReader(location, System.Text.Encoding.Default))36
{37
plainText = ParseHtml(sr.ReadToEnd());38
}39
//为结果集DataTable,Results添加个新行40
DataRow dr = this.Results.NewRow();41
dr["title"] = doc.Get("title");42
dr["path"] = @"documents/" + path;43
dr["sample"] = highlighter.GetBestFragment(plainText,80);44
//把行添加进DataTable45
this.Results.Rows.Add(dr);46
}47
//循环完毕,关闭搜索48
searcher.Close();49
//搜索花费多少时间50
this.duration = DateTime.Now - start;51
//给fromItem赋值,他总是startAt+152
this.fromItem = this.startAt + 1;53
//给toItem赋值54
this.toItem = smallOf(this.total,this.startAt+this.maxResults);55
56
}还有就是一个Paging属性,他的作用就是分页,输出分页的html这个属性很经典1
/**//// <summary>2
/// 开始分页3
/// </summary>4
/// <returns></returns>5
protected DataTable Paging6
{7
get8
{ 9
//知道了startAt,分页也很容易了,现在根据startAt得到当前是第几页,注意,现在这里的页数也是暂时从0开始的10
int pageNumber = (this.startAt + this.maxResults - 1) / this.maxResults;11
DataTable dt = new DataTable();12
dt.Columns.Add("html");13
DataRow dr = dt.NewRow();14
//暂时得到当前页的html连接,注意这里当真正显示页数的时候要+115
dr["html"] = pagingNumberHtml(startAt,pageNumber+1,false);16
dt.Rows.Add(dr);17
//前面显示10页,如果有的话18
int previousPagesCount = 10;19
//循环把前面页的html连接插到前面去 20
for (int i = pageNumber - 1; i >= 0 && i >= pageNumber - previousPagesCount; i--)21
{22
DataRow r = dt.NewRow();23
r["html"] = pagingNumberHtml(i*this.maxResults,i+1,true);24
dt.Rows.InsertAt(r,0);;25
}26
//后面也显示10页,如果有的话27
int nextPagesCount = 10;28
for (int i = pageNumber + 1; i <= this.pageCount && i <= pageNumber + nextPagesCount; i++)29
{30
DataRow r = dt.NewRow();31
r["html"] = pagingNumberHtml(i*this.maxResults,i+1,true);32
dt.Rows.Add(r);33
}34
//添加下一页的超级连接35
DataRow lastRow = dt.NewRow();36
lastRow["html"] = "<a href='Search.aspx?q="+this.Query+"&start="+(pageNumber+1)*this.maxResults+"'>下一页</a>";37
dt.Rows.Add(lastRow);38
return dt;39
40
}
编辑推荐DotLucene搜索引擎文章列表:
全文搜索解决方案:DotLucene搜索引擎之创建索引
http://www.xueit.com/html/2009-02/21_606_00.html
DotLucene搜索引擎之搜索索引Demo
http://www.xueit.com/html/2009-02/21_607_00.html
全文搜索技术:dotLucene中文分词的highlight显示
http://www.xueit.com/html/2009-02/21_608_00.html
Lucene.NET增加中文分词
http://www.xueit.com/html/2009-02/21_609_00.html
全文搜索之Lucene增加中文分词功能方法
http://www.xueit.com/html/2009-02/21_610_00.html
简介下基于.NET的全文索引引擎Lucene.NET
http://www.xueit.com/html/2009-02/21_611_00.html
使用dotlucene为数据库建立全文索引
http://www.xueit.com/html/2009-02/21_612_00.html
使用dotlucene多条件检索数据库
http://www.xueit.com/html/2009-02/21_613_00.html
Lucene中文分词实现方法:基于StopWord分割分词
http://www.xueit.com/html/2009-02/21_614_00.html
dotLucene实现增量索引源代码
http://www.xueit.com/html/2009-02/21_615_00.html
精彩图集
精彩文章