数据结构学习C++――图(1&2&3&4)
数据结构学习C++――图【1】(基本储存方法)
首先告诉大家一个好消息,数据结构到这里就要结束了!然后再来一个坏消息,这里是数据结构中“最没有意义”的部分和最难的部分。图的应用恐怕是所有结构中最宽泛的了,但这也注定了在讲“数据结构的图”的时候没什么好讲的――关于图的最重要的是算法,而且相当的一部分都是很专业的,一般的人几乎不会接触到;相对而言,结构就显得分量很轻。你可以看到关于图中元素的操作很少,远没有单链表那里列出的一大堆“接口”。――一个结构假如复杂,那么能确切定义的操作就很有限。
不管怎么说,还是先得把图存起来。不要看书上列出了好多方法,根本只有一个――邻接矩阵。假如矩阵是稀疏的,那就可以用十字链表来储存矩阵(见前面的《稀疏矩阵(十字链表)》)。假如我们只关系行的关系,那么就是邻接表(出边表);反之,只关心列的关系,就是逆邻接表(入边表)。
下面给出两种储存方法的实现。
#ifndef Graphmem_H
#define Graphmem_H
#include
#include
using namespace std;
template class Network;
const int maxV = 20;//最大节点数
template
class AdjMatrix
{
friend class Network >;
public:
AdjMatrix() : vNum(0), eNum(0)
{
vertex = new name[maxV]; edge = new dist*[maxV];
for (int i = 0; i < maxV; i++) edge[i] = new dist[maxV];
}
~AdjMatrix()
{
for (int i = 0; i < maxV; i++) delete []edge[i];
delete []edge; delete []vertex;
}
bool insertV(name v)
{
if (find(v)) return false;
vertex[vNum] = v;
for (int i = 0; i < maxV; i++) edge[vNum][i] = NoEdge;
vNum++; return true;
}
bool insertE(name v1, name v2, dist cost)
{
int i, j;
if (v1 == v2 !find(v1, i) !find(v2, j)) return false;
if (edge[i][j] != NoEdge) return false;
edge[i][j] = cost; eNum++; return true;
}
name& getV(int n) //没有越界检查
int nextV(int m, int n)//返回m号顶点的第n号顶点后第一个邻接顶点号,无返回-1
{
for (int i = n + 1; i < vNum; i++) if (edge[m][i] != NoEdge) return i;
return -1;
}
private:
int vNum, eNum;
dist NoEdge, **edge; name *vertex;
bool find(const name& v)
{
for (int i = 0; i < vNum; i++) if (v == vertex[i]) return true;
return false;
}
bool find(const name& v, int& i)
{
for (i = 0; i ;
public:
LinkedList() : vNum(0), eNum(0) {}
~LinkedList()
{
for (int i = 0; i begin();
iter != vertices[i].e->end() && iter->vID end())
{
vertices[i].e->push_back(edge(j, cost)); eNum++; return true;
}
if (iter->vID == j) return false;
vertices[i].e->insert(iter, edge(j, cost)); eNum++; return true;
}
name& getV(int n) //没有越界检查
int nextV(int m, int n)//返回m号顶点的第n号顶点后第一个邻接顶点号,无返回-1
{
for (list::iterator iter = vertices[m].e->begin();
iter != vertices[m].e->end(); iter++) if (iter->vID > n) return iter->vID;
return -1;
}
private:
bool find(const name& v)
{
for (int i = 0; i < vNum; i++) if (v == vertices[i].v) return true;
return false;
}
bool find(const name& v, int& i)
{
for (i = 0; i < vNum; i++) if (v == vertices[i].v) return true;
return false;
}
strUCt edge
{
edge() {}
edge(int vID, dist cost) : vID(vID), cost(cost) {}
int vID;
dist cost;
};
struct vertex
{
vertex() {}
vertex(name v, list* e) : v(v), e(e) {}
name v;
list* e;
};
int vNum, eNum;
vector vertices;
};
#endif
这个实现是很简陋的,但应该能满足后面的讲解了。现在这个还什么都不能做,不要急,在下篇将讲述图的DFS和BFS。
数据结构学习(C++)――图【2】(DFS和BFS) happycock(原作)
要害字 DFS BFS
对于非线性的结构,遍历都会首先成为一个问题。和二叉树的遍历一样,图也有深度优先搜索(DFS)和广度优先搜索(BFS)两种。不同的是,图中每个顶点没有了祖先和子孙的关系,因此,前序、中序、后序不再有意义了。仿照二叉树的遍历,很轻易就能完成DFS和BFS,只是要注重图中可能有回路,因此,必须对访问过的顶点做标记。
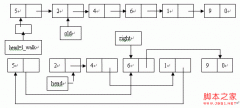
最基本的有向带权网
#ifndef Graph_H
#define Graph_H
#include
#include
using namespace std;
#include "Graphmem.h"
template
class Network
{
public:
Network() {}
Network(dist maxdist)
~Network() {}
bool insertV(name v)
bool insertE(name v1, name v2, dist cost)
name& getV(int n)
int nextV(int m, int n = -1)
int vNum()
int eNum()
protected:
bool* visited;
static void print(name v)
private:
mem data;
};
#endif
你可以看到,这是在以mem方式储存的data上面加了一层外壳。在图这里,逻辑上分有向、无向,带权、不带权;储存结构上有邻接矩阵和邻接表。也就是说分开来有8个类。为了最大限度的复用代码,继续关系就非常复杂了。但是,多重继续是件很讨厌的事,什么覆盖啊,还有什么虚拟继续,我可不想花大量篇幅讲语言特性。于是,我将储存方式作为第三个模板参数,这样一来就省得涉及虚拟继续了,只是这样一来这个Network的实例化就很麻烦了,不过这可以通过typedef或者外壳类来解决,我就不写了。反正只是为了让大家明白,真正要用的时候,最好是写专门的类,比如无向无权邻接矩阵图,不要搞的继续关系乱七八糟。
DFS和BFS的实现
public:
void DFS(void(*visit)(name v) = print)
{
visited = new bool[vNum()];
for (int i = 0; i < vNum(); i++) visited[i] = false;
DFS(0, visit);
delete []visited;
}
protected:
void DFS(int i, void(*visit)(name v) = print)
{
visit(getV(i)); visited[i] = true;
for (int n = nextV(i); n != -1; n = nextV(i, n))
if (!visited[n]) DFS(n, visit);
}
public:
void BFS(int i = 0, void(*visit)(name v) = print)//n没有越界检查
{
visited = new bool[vNum()]; queue a; int n;
for (n = 0; n a;
a.insertV('A'); a.insertV('B');
a.insertV('C'); a.insertV('D');
a.insertE('A', 'B', 1); a.insertE('A', 'C', 2);
a.insertE('B', 'D', 3);
cout << "DFS: "; a.DFS(); cout << endl;
cout << "BFS: "; a.BFS(); cout << endl;
return 0;
}
老实说,这个类用起来真的不是很方便。不过能说明问题就好。
数据结构学习(C++)――图【3】(无向图上) happycock(原作)
要害字 数据结构 C++ 连通分量 关节点
要是在纸上随便画画,或者只是对图做点示范性的说明,大多数人都会选择无向图。然而在计算机中,无向图却是按照有向图的方法来储存的――存两条有向边。实际上,当我们说到无向的时候,只是忽略方向――在纸上画一条线,难不成那线“嗖”的就出现了,不是从一头到另一头画出来的?
无向图有几个特有的概念,连通分量、关节点、最小生成树。下面将分别介绍,在此之前,先完成无向图类的基本操作。
无向图类
template
class Graph : public Network
{
public:
Graph() {}
Graph(dist maxdist) : Network (maxdist) {}
bool insertE(name v1, name v2, dist cost)
{
if (Network::insertE(v1, v2, cost))
return Network::insertE(v2, v1, cost);
return false;
}
};
仅仅是添加边的时候,再添加一条反向边,很简单。
连通分量
这是无向图特有的,有向图可要复杂多了(强、单、弱连通),原因就是无向图的边怎么走都行,有向图的边似乎掉下无底深渊就再也爬不上来了。有了DFS,求连通分量的算法就变得非常简单了――对每个没有访问的顶点调用DFS就可以了。
void components()
{
visited = new bool[vNum()]; int i, j = 0;
for (i = 0; i < vNum(); i++) visited[i] = false;
cout << "Components:" << endl;
for (i = 0; i = dfn[i]) cout <=就显得很尴尬了,因为只能等于不可能大于。还要注重的是,生成树的根(DFS的起始点)是单独判定的。
void articul()
{
dfn = new int[vNum()]; low = new int[vNum()]; int i, j = 0, n;
for(i = 0; i < vNum(); i++) dfn[i] = low[i] = 0;//初始化
for (i = 0; i < vNum(); i++)
{
if (!dfn[i])
{
cout << '(' << ++j << ')'; dfn[i] = low[i] = count = 1;
if ((n = nextV(i)) != -1) articul(n); bool out = false;//访问树根
while ((n = nextV(i, n)) != -1)
{
if (dfn[n]) continue;
if (!out) //树根有不只一个子女
articul(n);//访问其他子女
}
cout << endl;
}
}
delete []dfn; delete []low;
}
private:
void articul(int i)
{
dfn[i] = low[i] = ++count;
for (int n = nextV(i); n != -1; n = nextV(i, n))
{
if (!dfn[n])
{
articul(n);
if (low[n] = dfn[i]) cout << getV(i);//这里只可能=
}
else if (dfn[n] < low[i]) low[i] = dfn[n];//回边判定
}
}
int *dfn, *low, count;
数据结构学习(C++)――图【4】(无向图下) happycock(原作)
要害字 数据结构 最小生成树
最小生成树
说人是最难伺候的,真是一点不假。上面刚刚为了“提高可靠性”添加了几条多余的边,这会儿又来想办法怎么能以最小的代价把所有的顶点都连起来。可能正是人的这种精神才使得人类能够进步吧――看着现在3GHz的CPU真是眼红啊,我还在受500MHz的煎熬,然后再想想8086……
正如图的基本元素是顶点和边,从这两个方向出发,就能得到两个算法――Kruskal算法(从边出发)、Prim算法(从顶点出发)。据说还有别的方法,恕我参考资料有限,不能详查。
最小生成树的储存
显然用常用的树的储存方法来储存没有必要,虽然名曰“树”,实际上,这里谁是谁的“祖先”、“子孙”并不重要。因此,用如下的MSTedge结构数组来储存就可以了。
template
class MSTedge
{
public:
MSTedge() {}
MSTedge(int v1, int v2, dist cost) : v1(v1), v2(v2), cost(cost) {}
int v1, v2;
dist cost;
bool operator > (const MSTedge& v2)
bool operator < (const MSTedge& v2)
bool operator == (const MSTedge& v2)
};
Kruskal算法
最小生成树直白的讲就是,挑选N-1条不产生回路最短的边。Kruskal算法算是最直接的表达了这个思想――在剩余边中挑选一条最短的边,看是否产生回路,是放弃,不是选定然后重复这个步骤。说起来倒是很简单,做起来就不那么轻易了――判定是否产生回路需要并查集,在剩余边中找一条最短的边需要最小堆(并不需要对所有边排序,所以堆是最佳选择)。
Kruskal算法的复杂度是O(eloge),当e接近N^2时,可以看到这个算法不如O(N^2)的Prim算法,因此,他适合于稀疏图。而作为稀疏图,通常用邻接表来储存比较好。另外,对于邻接矩阵储存的图,Kruskal算法比Prim算法占不到什么便宜(初始还要扫描N^2条“边”)。因此,最好把Kruskal算法放在Link类里面。
template int Link::MinSpanTree(MSTedge* a)
{
MinHeap
MFSets V(vNum); list::iterator iter;
for (i = 0; i begin(); iter != vertices[i].e->end(); iter++)
E.insert(MSTedge(i, iter->vID, iter->cost));//建立边的堆
for (i = 0; i < eNum && l < vNum; i++)//Kruskal Start
{
j = V.find(E.top().v1); k = V.find(E.top().v2);
if (j != k)
E.pop();
}
return l;
}
下面是堆和并查集的实现
#ifndef Heap_H
#define Heap_H
#include
using namespace std;
#define minchild(i) (heap[i*2+1] template class MinHeap { public: void insert(const T& x) const T& top() void pop() private: void FilterUp(int i) { for (int j = (i - 1) / 2; j >= 0 && heap[j] > heap[i]; i = j, j = (i - 1) / 2) swap(heap[i], heap[j]); } void FilterDown(int i) { for (int j = minchild(i); j < heap.size() && heap[j] < heap[i]; i = j, j = minchild(i)) swap(heap[i], heap[j]); } vector heap; }; #endif #ifndef MFSets_H #define MFSets_H class MFSets { public: MFSets(int maxsize) : size(maxsize) { parent = new int[size + 1]; for (int i = 0; i <= size; i++) parent[i] = -1; } ~MFSets() void merge(int root1, int root2)//root1!=root2 { parent[root2] = root1; } int find(int n) { if (parent[n] < 0) return n; return find(parent[n]); } private: int size; int* parent; }; #endif Prim算法 假如从顶点入手,就能得到另一种方法。从只含有一个顶点的集合开始,寻找集合外面的顶点到这个集合里的顶点最近的一条边,然后将这个顶点加入集合,修改因为这个顶点的加入而使得集合外面的顶点到集合里的顶点的最短距离产生变化的分量。因为需要对每个顶点扫描,邻接矩阵储存的图是最合适Prim算法的。 template int AdjMatrix::MinSpanTree(MSTedge* a) { dist* lowC = new dist[vNum]; int* nearV = new int[vNum]; int i, j, k; for (i = 0; i < vNum; i++) nearV[0] = -1; for (k = 0; k < vNum-1; k++)//Prim Start { for (i = 1, j = 0; i < vNum; i++) if (nearV[i] != -1 && lowC[i] < lowC[j]) j = i;//find low cost a[k] = MSTedge(nearV[j], j, lowC[j]); nearV[j] = -1; //insert MST if (a[k].cost == NoEdge) return k - 1;//no edge then return for (i = 1; i < vNum; i++)//modify low cost if (nearV[i] != -1 && edge[i][j] < lowC[i]) } return k; } 【附注】这里需要说明一下,对于edge[I][I]这样的是应该是0呢还是NoEdge呢?显然0合理,但是不好用。并且,从有权图无权图统一的角度来说,是NoEdge更好。因此,在我的有权图的邻接矩阵中,主对角线上的元素是NoEdge,而不是书上的0。 测试程序 储存和操作分离,没想到得到了一个有趣的结果――对于最后的无向图而言,最小生成树的算法对外表现不知道是采用了那个算法。 template bool Graph::MinSpanTree() { MSTedge* a = new MSTedge[vNum() - 1]; int n = data.MinSpanTree(a); dist sum = dist(); if (n < vNum() - 1) return false;//不够N-1条边,不是生成树 for (int i = 0; i < n; i++) { cout << '(' << getV(a[i].v1) << ',' << getV(a[i].v2) << ')' << a[i].cost << ' '; sum += a[i].cost; } cout << endl << "MinCost: " << sum << endl; delete []a; return true; } 最后的测试图的数据取自殷版(C++)――不知是这组数据好是怎么的,殷版居然原封不动的照抄了《数据结构算法与应用-C++语言描述》(中文译名) #include using namespace std; #include "Graph.h" int main() { Graph a.insertV('A'); a.insertV('B'); a.insertV('C'); a.insertV('D'); a.insertV('E'); a.insertV('F'); a.insertV('G'); a.insertE('A', 'B', 28); a.insertE('A', 'F', 10); a.insertE('B', 'C', 16); a.insertE('C', 'D', 12); a.insertE('D', 'E', 22); a.insertE('B', 'G', 14); a.insertE('E', 'F', 25); a.insertE('D', 'G', 18); a.insertE('E', 'G', 24); a.MinSpanTree(); return 0; }
- 上一篇:双向链表的排序
- 下一篇:数据结构学习C++――图(4&5&总结&后记)