
数据结构学习(C++)之栈和队列[组图]
栈和队列是操作受限的线性表,似乎每本讲数据结构的数都是这么说的。有些书按照这个思路给出了定义和实现;但是很遗憾,本文没有这样做,所以,有些书中的做法是重复建设,这
栈和队列是操作受限的线性表,似乎每本讲数据结构的数都是这么说的。有些书按照这个思路给出了定义和实现;但是很遗憾,本文没有这样做,所以,有些书中的做法是重复建设,这或许可以用不是一个人写的这样的理由来开脱。
顺序表示的栈和队列,必须预先分配空间,并且空间大小受限,使用起来限制比较多。而且,由于限定存取位置,顺序表示的随机存取的优点就没有了,所以,链式结构应该是首选。
栈的定义和实现
#ifndef Stack_H
#define Stack_H
#include "List.h"
template <class Type> class Stack : List<Type>//栈类定义
{
public:
void Push(Type value)
{
Insert(value);
}
Type Pop()
{
Type p = *GetNext();
RemoveAfter();
return p;
}
Type GetTop()
{
return *GetNext();
}
List<Type> ::MakeEmpty;
List<Type> ::IsEmpty;
};
#endif 队列的定义和实现
#ifndef Queue_H
#define Queue_H
#include "List.h"
template <class Type> class Queue : List<Type>//队列定义
{
public:
void EnQueue(const Type &value)
{
LastInsert(value);
}
Type DeQueue()
{
Type p = *GetNext();
RemoveAfter();
IsEmpty();
return p;
}
Type GetFront()
{
return *GetNext();
}
List<Type> ::MakeEmpty;
List<Type> ::IsEmpty;
};
#endif 测试程序
#ifndef StackTest_H
#define StackTest_H
#include "Stack.h"
void StackTest_int()
{
cout << endl << "整型栈测试" << endl;
cout << endl << "构造一个空栈" << endl;
Stack<int> a;
cout << "将1~20入栈,然后再出栈" << endl;
for (int i = 1; i <= 20; i++) a.Push(i);
while (!a.IsEmpty()) cout << a.Pop() << ' ';
cout << endl;
}
#endif
#ifndef QueueTest_H
#define QueueTest_H
#include "Queue.h"
void QueueTest_int()
{
cout << endl << "整型队列测试" << endl;
cout << endl << "构造一个空队列" << endl;
Queue<int> a;
cout << "将1~20入队,然后再出队" << endl;
for (int i = 1; i <= 20; i++) a.EnQueue(i);
while (!a.IsEmpty()) cout << a.DeQueue() << ' ';
cout << endl;
}
#endif 没什么好说的,你可以清楚的看到,在单链表的基础上,栈和队列的实现是如此的简单。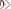 更多内容请看数据结构 数据结构教程 数据结构相关文章专题,或
栈应用
更多内容请看数据结构 数据结构教程 数据结构相关文章专题,或
栈应用
栈的应用很广泛,栈的最大的用途是解决回溯问题,这也包含了消解递归;而当你用栈解决回溯问题成了习惯的时候,你就很少想到用递归了,比如迷宫求解。另外,人的习惯也是先入为主的,比如树的遍历,从学的那天开始,就是递归算法,虽然书上也教了用栈实现的方法,但应用的时候,你首先想到的还是递归;当然了,假如语言本身不支持递归(如BASIC),那栈就是唯一的选择了――似乎现在的高级语言都是支持递归的。
如下是表达式类的定义和实现,表达式可以是中缀表示也可以是后缀表示,用头节点数据域里的type区分,这里有一点说明的是,由于单链表的赋值函数,我原来写的时候没有复制头节点的内容,所以,要是在两个表达式之间赋值,头节点里存的信息就丢了。你可以改写单链表的赋值函数来解决这个隐患,或者你根本不不在两个表达式之间赋值也行。
#ifndef EXPression_H
#define Expression_H
#include "List.h"
#include "Stack.h"
#define INFIX 0
#define POSTFIX 1
#define OPND 4
#define OPTR 8
template <class Type> class ExpNode
{
public:
int type;
union { Type opnd; char optr;};
ExpNode() : type(INFIX), optr('=') {}
ExpNode(Type opnd) : type(OPND), opnd(opnd) {}
ExpNode(char optr) : type(OPTR), optr(optr) {}
};
template <class Type> class Expression : List<ExpNode<Type> >
{
public:
void Input()
{
MakeEmpty(); Get()->type =INFIX;
cout << endl << "输入表达式,以=结束输入" << endl;
Type opnd; char optr = ' ';
while (optr != '=')
{
cin >> opnd;
if (opnd != 0)
{
ExpNode<Type> newopnd(opnd);
LastInsert(newopnd);
}
cin >> optr;
ExpNode<Type> newoptr(optr);
LastInsert(newoptr);
}
}
void Print()
{
First();
cout << endl;
for (ExpNode<Type> *p = Next(); p != NULL; p = Next() )
{
switch (p->type)
{
case OPND:
cout << p->opnd; break;
case OPTR:
cout << p->optr; break;
default: break;
}
cout << ' ';
}
cout << endl;
}
Expression & Postfix() //将中缀表达式转变为后缀表达式
{
First();
if (Get()->type == POSTFIX) return *this;
Stack<char> s; s.Push('=');
Expression temp;
ExpNode<Type> *p = Next();
while (p != NULL)
{
switch (p->type)
{
case OPND:
temp.LastInsert(*p); p = Next(); break;
case OPTR:
while (isp(s.GetTop()) > icp(p->optr) )
{
ExpNode<Type> newoptr(s.Pop());
temp.LastInsert(newoptr);
}
if (isp(s.GetTop()) == icp(p->optr) )
{
s.Pop(); p =Next(); break;
}
s.Push(p->optr); p = Next(); break;
default: break;
}
}
*this = temp;
pGetFirst()->data.type = POSTFIX;
return *this;
}
Type Calculate()
{
Expression temp = *this;
if (pGetFirst()->data.type != POSTFIX) temp.Postfix();
Stack<Type> s; Type left, right;
for (ExpNode<Type> *p = temp.Next(); p != NULL; p = temp.Next())
{
switch (p->type)
{
case OPND:
s.Push(p->opnd); break;
case OPTR:
right = s.Pop(); left = s.Pop();
switch (p->optr)
{
case '+': s.Push(left + right); break;
case '-': s.Push(left - right); break;
case '*': s.Push(left * right); break;
case '/': if (right != 0) s.Push(left/right); else return 0; break;
// case '%': if (right != 0) s.Push(left%right); else return 0; break;
// case '^': s.Push(Power(left, right)); break;
default: break;
}
default: break;
}
}
return s.Pop();
}
private:
int isp(char optr)
{
switch (optr)
{
case '=': return 0;
case '(': return 1;
case '^': return 7;
case '*': return 5;
case '/': return 5;
case '%': return 5;
case '+': return 3;
case '-': return 3;
case ')': return 8;
default: return 0;
}
}
int icp(char optr)
{
switch (optr)
{
case '=': return 0;
case '(': return 8;
case '^': return 6;
case '*': return 4;
case '/': return 4;
case '%': return 4;
case '+': return 2;
case '-': return 2;
case ')': return 1;
default: return 0;
}
}
};
#endif
几点说明
1、表达式用单链表储存,你可以看到这个链表中既有操作数又有操作符,假如你看过我的《如何在一个链表中链入不同类型的对象》,这里的方法也是对那篇文章的补充。
2、输入表达式时,会将原来的内容清空,并且必须按照中缀表示输入。假如你细看一下中缀表达式,你就会发现,除了括号,表达式的结构是“操作数”、“操作符”、“操作数”、……“操作符(=)”,为了统一这个规律,同时也为了使输入函数简单一点,规定括号必须这样输入“0(”、“)0”;这样一来,“0”就不能作为操作数出现在表达式中了。因为我没有在输入函数中增加容错的语句,所以一旦输错了,那程序就“死”了。
3、表达式求值的过程是,先变成后缀表示,然后用后缀表示求值。因为原书讲解的是这两个算法,并且用这两个算法就能完成中缀表达式的求值,所以我就没写中缀表达式的直接求值算法。具体算法说明参见原书,我就不废话了。
4、Calculate()注释掉的两行,“%”是因为只对整型表达式合法,“^”的Power()函数没有完成。
5、isp(),icp()的返回值,原书说的不细,我来多说两句。‘=’(表达式开始和结束标志)的栈内栈外优先级都是最低。‘(’栈外最高,栈内次最低。‘)’栈外次最低,不进栈。‘^’栈内次最高,栈外比栈内低。‘×÷%’栈内比‘^’栈外低,栈外比栈内低。‘+-’栈内比‘×’栈外低,栈外比栈内低。这样,综合起来,就有9个优先级,于是就得出了书上的那个表。 更多内容请看数据结构 数据结构教程 数据结构相关文章专题,或 队列应用
我看的两本教科书(《数据结构(C语言版)》还有这本黄皮书)都是以这个讲解队列应用的,而且都是银行营业模拟(太没新意了)。细比较,这两本书模拟的银行营业的方式还是不同的。![]()
![]()
![]()
![]() <!-- frame contents -->
<!-- /frame contents -->
<!-- frame contents -->
<!-- /frame contents -->
![]()
![]()
![]()
![]() 1997版的《数据结构(C语言版)》的银行还是老式的营业模式(究竟是1997年的事了),现在的很多地方还是这种营业模式――几个窗口同时排队。这种方式其实不太合理,经常会出现先来的还没有后来的先办理业务(经常前面一个人磨磨蹭蹭,别的队越来越短,让你恨不得把前面那人干掉)。1999版的这本黄皮书的银行改成了一种挂牌的营业方式,每个来到的顾客发一个号码,假如哪个柜台空闲了,就叫号码最靠前的顾客来办理业务;假如同时几个柜台空闲,就按照一种法则来决定这几个柜台叫号的顺序(最简单的是按柜台号码顺序)。这样,就能保证顾客按照先来后到的顺序接受服务――因为大家排在一个队里。这样的营业模式我在北京的西直门工商银行见过,应该说这是比较合理的一种营业模式。不过,在本文中最重要的是,这样的营业模式比较好模拟(一个队列总比N个队列好操作)。
1997版的《数据结构(C语言版)》的银行还是老式的营业模式(究竟是1997年的事了),现在的很多地方还是这种营业模式――几个窗口同时排队。这种方式其实不太合理,经常会出现先来的还没有后来的先办理业务(经常前面一个人磨磨蹭蹭,别的队越来越短,让你恨不得把前面那人干掉)。1999版的这本黄皮书的银行改成了一种挂牌的营业方式,每个来到的顾客发一个号码,假如哪个柜台空闲了,就叫号码最靠前的顾客来办理业务;假如同时几个柜台空闲,就按照一种法则来决定这几个柜台叫号的顺序(最简单的是按柜台号码顺序)。这样,就能保证顾客按照先来后到的顺序接受服务――因为大家排在一个队里。这样的营业模式我在北京的西直门工商银行见过,应该说这是比较合理的一种营业模式。不过,在本文中最重要的是,这样的营业模式比较好模拟(一个队列总比N个队列好操作)。
原书的这部分太难看了,我看的晕晕的,我也不知道按照原书的方法能不能做出来,因为我没看懂(旁白:靠,你小子这样还来现眼)。我按照实际情况模拟,实现如下:
#ifndef Simulation_H
#define Simulation_H
#include <iostream.h>
#include <stdlib.h>
#include <time.h>
class Teller
{
public:
int totalCustomerCount;
int totalServiceTime;
int finishServiceTime;
Teller() :totalCustomerCount(0), totalServiceTime(0),
finishServiceTime(0) {}
};
//#define PRINTPROCESS
class Simulation
{
public:
Simulation()
{
cout << endl << "输入模拟参数" << endl;
cout << "柜台数量:"; cin >> tellerNum;
cout << "营业时间:"; cin >> simuTime;
cout << "两个顾客来到的最小间隔时间:"; cin >> arrivalLow;
cout << "两个顾客来到的最大间隔时间:"; cin >> arrivalHigh;
cout << "柜台服务最短时间:"; cin >> serviceLow;
cout << "柜台服务最长时间:"; cin >> serviceHigh;
arrivalRange = arrivalHigh - arrivalLow + 1;
serviceRange = serviceHigh - serviceLow + 1;
srand((unsigned)time(NULL));
}
Simulation(int tellerNum, int simuTime, int arrivalLow, int arrivalHigh, int serviceLow, int serviceHigh)
: tellerNum(tellerNum), simuTime(simuTime), arrivalLow(arrivalLow), arrivalHigh(arrivalHigh),
serviceLow(serviceLow), serviceHigh(serviceHigh),
arrivalRange(arrivalHigh - arrivalLow + 1), serviceRange(serviceHigh - serviceLow + 1)
{ srand((unsigned)time(NULL)); }
void Initialize()
{
curTime = nextTime = 0;
customerNum = customerTime = 0;
for (int i = 1; i <= tellerNum; i++)
{
tellers[i].totalCustomerCount = 0;
tellers[i].totalServiceTime = 0;
tellers[i].finishServiceTime = 0;
}
customer.MakeEmpty();
}
void Run()
{
Initialize();
NextArrived();
#ifdef PRINTPROCESS
cout << endl;
cout << "tellerID";
for (int k = 1; k <= tellerNum; k++) cout << " TELLER " << k;
cout << endl;
#endif
for (curTime = 0; curTime <= simuTime; curTime++)
{
if (curTime >= nextTime)
{
CustomerArrived();
NextArrived();
}
#ifdef PRINTPROCESS
cout << "Time: " << curTime << " ";
#endif
for (int i = 1; i <= tellerNum; i++)
{
if (tellers[i].finishServiceTime < curTime) tellers[i].finishServiceTime = curTime;
if (tellers[i].finishServiceTime == curTime && !customer.IsEmpty())
{
int t = NextService();
#ifdef PRINTPROCESS
cout << ' ' << customerNum + 1 << '(' << customer.GetFront() << ',' << t << ')';
#endif
CustomerDeparture();
tellers[i].totalCustomerCount++;
tellers[i].totalServiceTime += t;
tellers[i].finishServiceTime += t;
}
#ifdef PRINTPROCESS
else cout << " ";
#endif
}
#ifdef PRINTPROCESS
cout << endl;
#endif
}
PrintResult();
}
void PtintSimuPara()
{
cout << endl << "模拟参数" << endl;
cout << "柜台数量: " << tellerNum << " 营业时间:" << simuTime << endl;
cout << "两个顾客来到的最小间隔时间:" << arrivalLow << endl;
cout << "两个顾客来到的最大间隔时间:" << arrivalHigh << endl;;
cout << "柜台服务最短时间:" << serviceLow << endl;
cout << "柜台服务最长时间:" << serviceHigh << endl;
}
void PrintResult()
{
int tSN = 0;
long tST = 0;
cout << endl;
cout << "-------------模拟结果-------------------";
cout << endl << "tellerID ServiceNum ServiceTime AverageTime" << endl;
for (int i = 1; i <= tellerNum; i++)
{
cout << "TELLER " << i;
cout << ' ' << tellers[i].totalCustomerCount << " "; tSN += tellers[i].totalCustomerCount;
cout << ' ' << tellers[i].totalServiceTime << " "; tST += (long)tellers[i].totalServiceTime;
cout << ' ';
if (tellers[i].totalCustomerCount)
cout << (float)tellers[i].totalServiceTime/(float)tellers[i].totalCustomerCount;
else cout << 0;
cout << " " << endl;
}
cout << "TOTAL " << tSN << " " << tST << " ";
if (tSN) cout << (float)tST/(float)tSN; else cout << 0;
cout << " " << endl;
cout << "Customer Number: " << customerNum << " no Service: " << customerNum - tSN << endl;
cout << "Customer WaitTime: " << customerTime << " AvgWaitTime: ";
if (tSN) cout << (float)customerTime/(float)tSN; else cout << 0;
cout << endl;
}
private:
int tellerNum;
int simuTime;
int curTime, nextTime;
int customerNum;
long customerTime;
int arrivalLow, arrivalHigh, arrivalRange;
int serviceLow, serviceHigh, serviceRange;
Teller tellers[21];
Queue<int> customer;
void NextArrived()
{
nextTime += arrivalLow + rand() % arrivalRange;
}
int NextService()
{
return serviceLow + rand() % serviceRange;
}
void CustomerArrived()
{
customerNum++;
customer.EnQueue(nextTime);
}
void CustomerDeparture()
{
customerTime += (long)curTime - (long)customer.DeQueue();
}
};
#endif
几点说明
1、Run()的过程是这样的:curTime是时钟,从开始营业计时,自然流逝到停止营业。当顾客到的事件发生时(顾客到时间等于当前时间,小于判定是因为个别时候顾客同时到达――输入arrivalLow=0的情况,而在同一时间,只给一个顾客发号码),给这个顾客发号码(用顾客到时间标示这个顾客,入队,来到顾客数增1)。当柜台服务完毕时(柜台服务完时间等于当前时间),该柜台服务人数增1,服务时间累加,顾客离开事件发生,下一个顾客到该柜台。因为柜台开始都是空闲的,所以实际代码和这个有点出入。最后,停止营业的时候,停止发号码,还在接受服务的顾客继续到服务完,其他还在排队的就散伙了。
2、模拟结果分别是:各个柜台的服务人数、服务时间、平均服务时间,总的服务人数、服务时间、平均服务时间,来的顾客总数、没被服务的数目(来的太晚了)、接受服务顾客总等待时间、平均等待时间。
3、这个算法效率是比较低的,实际上可以不用队列完成这个模拟(用顾客到时间推动当前时钟,柜台直接公告服务完成时间),但这样就和实际情况有很大差别了――出纳员没等看见人就知道什么时候完?虽然结果是一样的,但是理解起来很莫名其妙,尤其是作为教学目的讲解的时候。当然了,实际中为了提高模拟效率,本文的这个算法是不值得提倡的。
4、注释掉的#define PRINTPROCESS,去掉注释符后,在运行模拟的时候,能打印出每个时刻柜台的服务情况(第几个顾客,顾客到达时间,接受服务时间),但只限4个柜台以下,多了的话屏幕就满了(格式就乱了)。
这是数据结构中第一个实际应用的例子,而且也有现实意义。你可以看出各个柜台在不同的业务密度下的工作强度(要么给哪个柜台出纳员发奖金,要么轮换柜台),各种情况下顾客的等待时间(人都是轮到自己就不着急了),还有各种情况下设立几个柜台合理(很少的空闲时间,很短的等待时间,几乎为零的未服务人数)。例如这样:
for (int i = 1; i < 16; i++)
{
Simulation a(i,240,1,4,8,15);
a.Run();
} 你模拟一下就会得出,在不太繁忙的银行,4~5个柜台是合适的――现在的银行大部分都是这样的。
更多内容请看数据结构 数据结构教程 数据结构相关文章专题,或
顺序表示的栈和队列,必须预先分配空间,并且空间大小受限,使用起来限制比较多。而且,由于限定存取位置,顺序表示的随机存取的优点就没有了,所以,链式结构应该是首选。
栈的定义和实现
#ifndef Stack_H
#define Stack_H
#include "List.h"
template <class Type> class Stack : List<Type>//栈类定义
{
public:
void Push(Type value)
{
Insert(value);
}
Type Pop()
{
Type p = *GetNext();
RemoveAfter();
return p;
}
Type GetTop()
{
return *GetNext();
}
List<Type> ::MakeEmpty;
List<Type> ::IsEmpty;
};
#endif 队列的定义和实现
#ifndef Queue_H
#define Queue_H
#include "List.h"
template <class Type> class Queue : List<Type>//队列定义
{
public:
void EnQueue(const Type &value)
{
LastInsert(value);
}
Type DeQueue()
{
Type p = *GetNext();
RemoveAfter();
IsEmpty();
return p;
}
Type GetFront()
{
return *GetNext();
}
List<Type> ::MakeEmpty;
List<Type> ::IsEmpty;
};
#endif 测试程序
#ifndef StackTest_H
#define StackTest_H
#include "Stack.h"
void StackTest_int()
{
cout << endl << "整型栈测试" << endl;
cout << endl << "构造一个空栈" << endl;
Stack<int> a;
cout << "将1~20入栈,然后再出栈" << endl;
for (int i = 1; i <= 20; i++) a.Push(i);
while (!a.IsEmpty()) cout << a.Pop() << ' ';
cout << endl;
}
#endif
#ifndef QueueTest_H
#define QueueTest_H
#include "Queue.h"
void QueueTest_int()
{
cout << endl << "整型队列测试" << endl;
cout << endl << "构造一个空队列" << endl;
Queue<int> a;
cout << "将1~20入队,然后再出队" << endl;
for (int i = 1; i <= 20; i++) a.EnQueue(i);
while (!a.IsEmpty()) cout << a.DeQueue() << ' ';
cout << endl;
}
#endif 没什么好说的,你可以清楚的看到,在单链表的基础上,栈和队列的实现是如此的简单。
更多内容请看数据结构 数据结构教程 数据结构相关文章专题,或
栈应用栈的应用很广泛,栈的最大的用途是解决回溯问题,这也包含了消解递归;而当你用栈解决回溯问题成了习惯的时候,你就很少想到用递归了,比如迷宫求解。另外,人的习惯也是先入为主的,比如树的遍历,从学的那天开始,就是递归算法,虽然书上也教了用栈实现的方法,但应用的时候,你首先想到的还是递归;当然了,假如语言本身不支持递归(如BASIC),那栈就是唯一的选择了――似乎现在的高级语言都是支持递归的。
如下是表达式类的定义和实现,表达式可以是中缀表示也可以是后缀表示,用头节点数据域里的type区分,这里有一点说明的是,由于单链表的赋值函数,我原来写的时候没有复制头节点的内容,所以,要是在两个表达式之间赋值,头节点里存的信息就丢了。你可以改写单链表的赋值函数来解决这个隐患,或者你根本不不在两个表达式之间赋值也行。
#ifndef EXPression_H
#define Expression_H
#include "List.h"
#include "Stack.h"
#define INFIX 0
#define POSTFIX 1
#define OPND 4
#define OPTR 8
template <class Type> class ExpNode
{
public:
int type;
union { Type opnd; char optr;};
ExpNode() : type(INFIX), optr('=') {}
ExpNode(Type opnd) : type(OPND), opnd(opnd) {}
ExpNode(char optr) : type(OPTR), optr(optr) {}
};
template <class Type> class Expression : List<ExpNode<Type> >
{
public:
void Input()
{
MakeEmpty(); Get()->type =INFIX;
cout << endl << "输入表达式,以=结束输入" << endl;
Type opnd; char optr = ' ';
while (optr != '=')
{
cin >> opnd;
if (opnd != 0)
{
ExpNode<Type> newopnd(opnd);
LastInsert(newopnd);
}
cin >> optr;
ExpNode<Type> newoptr(optr);
LastInsert(newoptr);
}
}
void Print()
{
First();
cout << endl;
for (ExpNode<Type> *p = Next(); p != NULL; p = Next() )
{
switch (p->type)
{
case OPND:
cout << p->opnd; break;
case OPTR:
cout << p->optr; break;
default: break;
}
cout << ' ';
}
cout << endl;
}
Expression & Postfix() //将中缀表达式转变为后缀表达式
{
First();
if (Get()->type == POSTFIX) return *this;
Stack<char> s; s.Push('=');
Expression temp;
ExpNode<Type> *p = Next();
while (p != NULL)
{
switch (p->type)
{
case OPND:
temp.LastInsert(*p); p = Next(); break;
case OPTR:
while (isp(s.GetTop()) > icp(p->optr) )
{
ExpNode<Type> newoptr(s.Pop());
temp.LastInsert(newoptr);
}
if (isp(s.GetTop()) == icp(p->optr) )
{
s.Pop(); p =Next(); break;
}
s.Push(p->optr); p = Next(); break;
default: break;
}
}
*this = temp;
pGetFirst()->data.type = POSTFIX;
return *this;
}
Type Calculate()
{
Expression temp = *this;
if (pGetFirst()->data.type != POSTFIX) temp.Postfix();
Stack<Type> s; Type left, right;
for (ExpNode<Type> *p = temp.Next(); p != NULL; p = temp.Next())
{
switch (p->type)
{
case OPND:
s.Push(p->opnd); break;
case OPTR:
right = s.Pop(); left = s.Pop();
switch (p->optr)
{
case '+': s.Push(left + right); break;
case '-': s.Push(left - right); break;
case '*': s.Push(left * right); break;
case '/': if (right != 0) s.Push(left/right); else return 0; break;
// case '%': if (right != 0) s.Push(left%right); else return 0; break;
// case '^': s.Push(Power(left, right)); break;
default: break;
}
default: break;
}
}
return s.Pop();
}
private:
int isp(char optr)
{
switch (optr)
{
case '=': return 0;
case '(': return 1;
case '^': return 7;
case '*': return 5;
case '/': return 5;
case '%': return 5;
case '+': return 3;
case '-': return 3;
case ')': return 8;
default: return 0;
}
}
int icp(char optr)
{
switch (optr)
{
case '=': return 0;
case '(': return 8;
case '^': return 6;
case '*': return 4;
case '/': return 4;
case '%': return 4;
case '+': return 2;
case '-': return 2;
case ')': return 1;
default: return 0;
}
}
};
#endif
几点说明
1、表达式用单链表储存,你可以看到这个链表中既有操作数又有操作符,假如你看过我的《如何在一个链表中链入不同类型的对象》,这里的方法也是对那篇文章的补充。
2、输入表达式时,会将原来的内容清空,并且必须按照中缀表示输入。假如你细看一下中缀表达式,你就会发现,除了括号,表达式的结构是“操作数”、“操作符”、“操作数”、……“操作符(=)”,为了统一这个规律,同时也为了使输入函数简单一点,规定括号必须这样输入“0(”、“)0”;这样一来,“0”就不能作为操作数出现在表达式中了。因为我没有在输入函数中增加容错的语句,所以一旦输错了,那程序就“死”了。
3、表达式求值的过程是,先变成后缀表示,然后用后缀表示求值。因为原书讲解的是这两个算法,并且用这两个算法就能完成中缀表达式的求值,所以我就没写中缀表达式的直接求值算法。具体算法说明参见原书,我就不废话了。
4、Calculate()注释掉的两行,“%”是因为只对整型表达式合法,“^”的Power()函数没有完成。
5、isp(),icp()的返回值,原书说的不细,我来多说两句。‘=’(表达式开始和结束标志)的栈内栈外优先级都是最低。‘(’栈外最高,栈内次最低。‘)’栈外次最低,不进栈。‘^’栈内次最高,栈外比栈内低。‘×÷%’栈内比‘^’栈外低,栈外比栈内低。‘+-’栈内比‘×’栈外低,栈外比栈内低。这样,综合起来,就有9个优先级,于是就得出了书上的那个表。
更多内容请看数据结构 数据结构教程 数据结构相关文章专题,或 队列应用我看的两本教科书(《数据结构(C语言版)》还有这本黄皮书)都是以这个讲解队列应用的,而且都是银行营业模拟(太没新意了)。细比较,这两本书模拟的银行营业的方式还是不同的。
原书的这部分太难看了,我看的晕晕的,我也不知道按照原书的方法能不能做出来,因为我没看懂(旁白:靠,你小子这样还来现眼)。我按照实际情况模拟,实现如下:
#ifndef Simulation_H
#define Simulation_H
#include <iostream.h>
#include <stdlib.h>
#include <time.h>
class Teller
{
public:
int totalCustomerCount;
int totalServiceTime;
int finishServiceTime;
Teller() :totalCustomerCount(0), totalServiceTime(0),
finishServiceTime(0) {}
};
//#define PRINTPROCESS
class Simulation
{
public:
Simulation()
{
cout << endl << "输入模拟参数" << endl;
cout << "柜台数量:"; cin >> tellerNum;
cout << "营业时间:"; cin >> simuTime;
cout << "两个顾客来到的最小间隔时间:"; cin >> arrivalLow;
cout << "两个顾客来到的最大间隔时间:"; cin >> arrivalHigh;
cout << "柜台服务最短时间:"; cin >> serviceLow;
cout << "柜台服务最长时间:"; cin >> serviceHigh;
arrivalRange = arrivalHigh - arrivalLow + 1;
serviceRange = serviceHigh - serviceLow + 1;
srand((unsigned)time(NULL));
}
Simulation(int tellerNum, int simuTime, int arrivalLow, int arrivalHigh, int serviceLow, int serviceHigh)
: tellerNum(tellerNum), simuTime(simuTime), arrivalLow(arrivalLow), arrivalHigh(arrivalHigh),
serviceLow(serviceLow), serviceHigh(serviceHigh),
arrivalRange(arrivalHigh - arrivalLow + 1), serviceRange(serviceHigh - serviceLow + 1)
{ srand((unsigned)time(NULL)); }
void Initialize()
{
curTime = nextTime = 0;
customerNum = customerTime = 0;
for (int i = 1; i <= tellerNum; i++)
{
tellers[i].totalCustomerCount = 0;
tellers[i].totalServiceTime = 0;
tellers[i].finishServiceTime = 0;
}
customer.MakeEmpty();
}
void Run()
{
Initialize();
NextArrived();
#ifdef PRINTPROCESS
cout << endl;
cout << "tellerID";
for (int k = 1; k <= tellerNum; k++) cout << " TELLER " << k;
cout << endl;
#endif
for (curTime = 0; curTime <= simuTime; curTime++)
{
if (curTime >= nextTime)
{
CustomerArrived();
NextArrived();
}
#ifdef PRINTPROCESS
cout << "Time: " << curTime << " ";
#endif
for (int i = 1; i <= tellerNum; i++)
{
if (tellers[i].finishServiceTime < curTime) tellers[i].finishServiceTime = curTime;
if (tellers[i].finishServiceTime == curTime && !customer.IsEmpty())
{
int t = NextService();
#ifdef PRINTPROCESS
cout << ' ' << customerNum + 1 << '(' << customer.GetFront() << ',' << t << ')';
#endif
CustomerDeparture();
tellers[i].totalCustomerCount++;
tellers[i].totalServiceTime += t;
tellers[i].finishServiceTime += t;
}
#ifdef PRINTPROCESS
else cout << " ";
#endif
}
#ifdef PRINTPROCESS
cout << endl;
#endif
}
PrintResult();
}
void PtintSimuPara()
{
cout << endl << "模拟参数" << endl;
cout << "柜台数量: " << tellerNum << " 营业时间:" << simuTime << endl;
cout << "两个顾客来到的最小间隔时间:" << arrivalLow << endl;
cout << "两个顾客来到的最大间隔时间:" << arrivalHigh << endl;;
cout << "柜台服务最短时间:" << serviceLow << endl;
cout << "柜台服务最长时间:" << serviceHigh << endl;
}
void PrintResult()
{
int tSN = 0;
long tST = 0;
cout << endl;
cout << "-------------模拟结果-------------------";
cout << endl << "tellerID ServiceNum ServiceTime AverageTime" << endl;
for (int i = 1; i <= tellerNum; i++)
{
cout << "TELLER " << i;
cout << ' ' << tellers[i].totalCustomerCount << " "; tSN += tellers[i].totalCustomerCount;
cout << ' ' << tellers[i].totalServiceTime << " "; tST += (long)tellers[i].totalServiceTime;
cout << ' ';
if (tellers[i].totalCustomerCount)
cout << (float)tellers[i].totalServiceTime/(float)tellers[i].totalCustomerCount;
else cout << 0;
cout << " " << endl;
}
cout << "TOTAL " << tSN << " " << tST << " ";
if (tSN) cout << (float)tST/(float)tSN; else cout << 0;
cout << " " << endl;
cout << "Customer Number: " << customerNum << " no Service: " << customerNum - tSN << endl;
cout << "Customer WaitTime: " << customerTime << " AvgWaitTime: ";
if (tSN) cout << (float)customerTime/(float)tSN; else cout << 0;
cout << endl;
}
private:
int tellerNum;
int simuTime;
int curTime, nextTime;
int customerNum;
long customerTime;
int arrivalLow, arrivalHigh, arrivalRange;
int serviceLow, serviceHigh, serviceRange;
Teller tellers[21];
Queue<int> customer;
void NextArrived()
{
nextTime += arrivalLow + rand() % arrivalRange;
}
int NextService()
{
return serviceLow + rand() % serviceRange;
}
void CustomerArrived()
{
customerNum++;
customer.EnQueue(nextTime);
}
void CustomerDeparture()
{
customerTime += (long)curTime - (long)customer.DeQueue();
}
};
#endif
几点说明
1、Run()的过程是这样的:curTime是时钟,从开始营业计时,自然流逝到停止营业。当顾客到的事件发生时(顾客到时间等于当前时间,小于判定是因为个别时候顾客同时到达――输入arrivalLow=0的情况,而在同一时间,只给一个顾客发号码),给这个顾客发号码(用顾客到时间标示这个顾客,入队,来到顾客数增1)。当柜台服务完毕时(柜台服务完时间等于当前时间),该柜台服务人数增1,服务时间累加,顾客离开事件发生,下一个顾客到该柜台。因为柜台开始都是空闲的,所以实际代码和这个有点出入。最后,停止营业的时候,停止发号码,还在接受服务的顾客继续到服务完,其他还在排队的就散伙了。
2、模拟结果分别是:各个柜台的服务人数、服务时间、平均服务时间,总的服务人数、服务时间、平均服务时间,来的顾客总数、没被服务的数目(来的太晚了)、接受服务顾客总等待时间、平均等待时间。
3、这个算法效率是比较低的,实际上可以不用队列完成这个模拟(用顾客到时间推动当前时钟,柜台直接公告服务完成时间),但这样就和实际情况有很大差别了――出纳员没等看见人就知道什么时候完?虽然结果是一样的,但是理解起来很莫名其妙,尤其是作为教学目的讲解的时候。当然了,实际中为了提高模拟效率,本文的这个算法是不值得提倡的。
4、注释掉的#define PRINTPROCESS,去掉注释符后,在运行模拟的时候,能打印出每个时刻柜台的服务情况(第几个顾客,顾客到达时间,接受服务时间),但只限4个柜台以下,多了的话屏幕就满了(格式就乱了)。
这是数据结构中第一个实际应用的例子,而且也有现实意义。你可以看出各个柜台在不同的业务密度下的工作强度(要么给哪个柜台出纳员发奖金,要么轮换柜台),各种情况下顾客的等待时间(人都是轮到自己就不着急了),还有各种情况下设立几个柜台合理(很少的空闲时间,很短的等待时间,几乎为零的未服务人数)。例如这样:
for (int i = 1; i < 16; i++)
{
Simulation a(i,240,1,4,8,15);
a.Run();
} 你模拟一下就会得出,在不太繁忙的银行,4~5个柜台是合适的――现在的银行大部分都是这样的。
更多内容请看数据结构 数据结构教程 数据结构相关文章专题,或精彩图集


精彩文章