经典四讲贯通C++排序之三 交换排序(1)(2)
快速排序
真为这个算法感到悲哀,连一个能表明算法实质的名字(比如直插、表插)都没有,也不像希尔排序是以发明人的名字命名的,难道就是因为它太快了?也许“快速”是对一个排序算法最高的荣誉吧。
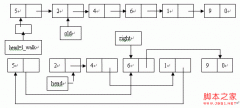
基本思想是:任取待排序列的某个记录作为基准,按照该关键码大小,将整个序列分成两个序列――左侧的所有记录的关键码都比基准小(或者等),右侧的都比基准大,基准则放在两个子序列之间,显然这时基准放在了最后应该放置的位置。分别对左右子序列重复上面的过程,直到最后所有的记录都放在相应的位置。
下面的例程不容易看懂,因为这是几次改进之后的样子:
- template <class T>
- int Partition(T a[], int left, int right, int& KCN, int& RMN)
- {
- int pivotpos = left; T pivot = a[left];//枢轴
- for (int i = left + 1; i <= right; i++)
- if (++KCN && a[i] < pivot && ++pivotpos != i)
- { swap(a[i], a[pivotpos]); RMN += 3;}
- swap(a[left], a[pivotpos]); RMN += 3;
- return pivotpos;
- }
将计算枢轴位置单独作为一个函数,可以避免递归的时候保存无用的临时变量。当你决定使用递归的时候,都要注意这点――将一切可以放在递归外面的都放在外面。注意这个函数是怎样达到我们“枢轴左边都比它小,右边都比它大”的目的。
- template <class T>
- void QSRecurve(T a[], int left, int right, int& KCN, int& RMN)
- {
- if (left < right)
- {
- int pivotpos = Partition
(a, left, right, KCN, RMN); - QSRecurve
(a, left, pivotpos - 1, KCN, RMN); - QSRecurve
(a, pivotpos + 1, right, KCN, RMN); - }
- }
- template <class T>
- void QuickSort(T a[], int N, int& KCN, int& RMN)
- {
- KCN = 0; RMN = 0;
- QSRecurve
(a, 0, N - 1, KCN, RMN); - }
这两个只能算个外壳了,尤其是最后一个。
测试结果:
- Sort ascending N=10000 TimeSpared: 1051ms
- KCN=49995000 KCN/N=4999.5 KCN/N^2=0.49995 KCN/NlogN=376.25
- RMN=29997 RMN/N=2.9997 RMN/N^2=0.00029997 RMN/NlogN=0.22575
- Sort randomness N=10000 TimeSpared: 0ms
- KCN=155655 KCN/N=15.5655 KCN/N^2=0.00155655 KCN/NlogN=1.17142
- RMN=211851 RMN/N=21.1851 RMN/N^2=0.00211851 RMN/NlogN=1.59434
- Sort descending N=10000 TimeSpared: 1082ms
- KCN=49995000 KCN/N=4999.5 KCN/N^2=0.49995 KCN/NlogN=376.25
- RMN=29997 RMN/N=2.9997 RMN/N^2=0.00029997 RMN/NlogN=0.22575
可以看到,平均性能非常好,但是在两端的性能还不如直插。测试N=100000的情况如下(千万记住把正序和逆序的测试注释掉,否则,到时候“死机”不要找我)
- Sort randomness N=100000 TimeSpared: 110ms
- KCN=2123221 KCN/N=21.2322 KCN/N^2=0.000212322KCN/NlogN=1.27831
- RMN=3010848 RMN/N=30.1085 RMN/N^2=0.000301085RMN/NlogN=1.81271
确实非常的“快速”,但是它的最坏情况实在让人不能放心,万一……,并且由于使用堆栈递归,出了最坏情况没准程序就崩溃了。为了减低这种不良倾向,改进办法是“三者取中”,即选取待排序序列的第一个、最后一个、中间一个的关键码居中的那个作为基准。只要改一下Partition函数就可以了。
- template <class T>
- int Partition(T a[], int left, int right, int& KCN, int& RMN)
- {
- int mid = (left + right) / 2;
- if (++KCN && a[left] > a[mid])
- {
- if (++KCN && a[left] > a[right])
- {
- if (++KCN && a[mid] > a[right]) { swap(a[mid], a[left]); RMN += 3; }
- else { swap(a[right], a[left]); RMN += 3; }
- }
- }
- else
- {
- if (++KCN && a[left] < a[right])
- {
- if (++KCN && a[mid] < a[right]) { swap(a[mid], a[left]); RMN += 3; }
- else { swap(a[right], a[left]); RMN += 3; }
- }
- }
- int pivotpos = left; T pivot = a[left];//枢轴
- for (int i = left + 1; i <= right; i++)
- if (++KCN && a[i] < pivot && ++pivotpos != i) { swap(a[i], a[pivotpos]); RMN += 3;}
- swap(a[left], a[pivotpos]); RMN += 3;
- return pivotpos;
- }
只是在原有的Partition函数上添加了粗体部分。下面是测试结果:
- Sort ascending N=10000 TimeSpared: 0ms
- KCN=131343 KCN/N=13.1343 KCN/N^2=0.00131343 KCN/NlogN=0.988455
- RMN=35424 RMN/N=3.5424 RMN/N^2=0.00035424 RMN/NlogN=0.266592
- Sort randomness N=10000 TimeSpared: 0ms
- KCN=154680 KCN/N=15.468 KCN/N^2=0.0015468 KCN/NlogN=1.16408
- RMN=204093 RMN/N=20.4093 RMN/N^2=0.00204093 RMN/NlogN=1.53595
- Sort descending N=10000 TimeSpared: 280ms
- KCN=12517506 KCN/N=1251.75 KCN/N^2=0.125175 KCN/NlogN=94.2036
- RMN=45006 RMN/N=4.5006 RMN/N^2=0.00045006 RMN/NlogN=0.338704
下面是N=100000的测试结果,在逆序的时候还是很尴尬,不过还算说得过去。
- Sort ascending N=100000 TimeSpared: 60ms
- KCN=1665551 KCN/N=16.6555 KCN/N^2=0.000166555KCN/NlogN=1.00276
- RMN=393210 RMN/N=3.9321 RMN/N^2=3.9321e-005RMN/NlogN=0.236736
- Sort randomness N=100000 TimeSpared: 110ms
- KCN=1888590 KCN/N=18.8859 KCN/N^2=0.000188859KCN/NlogN=1.13704
- RMN=2659857 RMN/N=26.5986 RMN/N^2=0.000265986RMN/NlogN=1.60139
- Sort descending N=100000 TimeSpared: 42120ms
- KCN=1250175006 KCN/N=12501.8 KCN/N^2=0.125018 KCN/NlogN=752.68
- RMN=450006 RMN/N=4.50006 RMN/N^2=4.50006e-005RMN/NlogN=0.270931
然而实际上,我们花那么多语句搞一个“三者取中”还不如直接“随便选一个”来得高效,例如将下面的语句替换掉原来的粗体语句:
- swap(a[left], a[rnd(right-left)+left]); RMN += 3;
测试结果:
- Sort ascending N=100000 TimeSpared: 90ms
- KCN=1917756 KCN/N=19.1776 KCN/N^2=0.000191776KCN/NlogN=1.1546
- RMN=378810 RMN/N=3.7881 RMN/N^2=3.7881e-005RMN/NlogN=0.228066
- Sort randomness N=100000 TimeSpared: 120ms
- KCN=1979189 KCN/N=19.7919 KCN/N^2=0.000197919KCN/NlogN=1.19159
- RMN=3175977 RMN/N=31.7598 RMN/N^2=0.000317598RMN/NlogN=1.91213
- Sort descending N=100000 TimeSpared: 110ms
- KCN=2069369 KCN/N=20.6937 KCN/N^2=0.000206937KCN/NlogN=1.24588
- RMN=2574174 RMN/N=25.7417 RMN/N^2=0.000257417RMN/NlogN=1.54981
可以看到逆序的效率有了质的飞跃,随机函数得自己写,因为库函数的rand()最大只能输出0x7fff,这是因为rand函数使用的是32bit的整数,为了不溢出(最严重的是出负数),只能输出那么大。一个不太严格的随机函数如下,最大输出值是32bit的最大正整数:
- int rnd(int n)
- {
- static _int64 x;
- x = (2053 * x + 13849) % 0x7fffffff;
- return (int)x % n;
- }